MassiveBLAST
イルミナ社の次世代シーケンサーGenome Analyzer (solexa) によって得られた大量のリードを、任意のBLASTデータベースに対してBLAST検索を行い、相同性が見られるリードを抽出する機能です。大量リードを分割し、また分散コンピューティングXgridを利用することでより高速な処理が可能です。メタゲノムDNA由来のリードを解析するために作成しました。multi FASTA形式のデータを基にBLASTデータベースを作成するGUIもついています。
はじめに
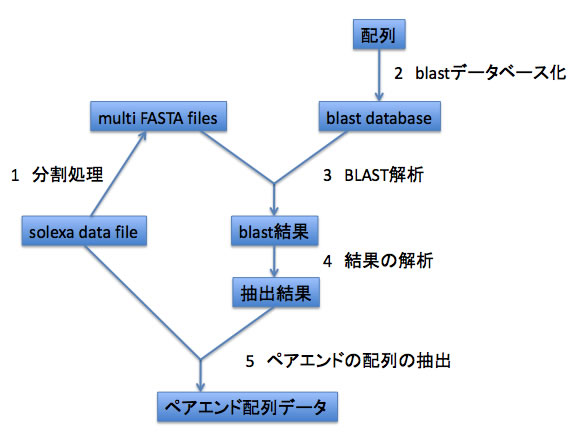
MassiveBLASTを利用して、solexaデータファイルから任意のデータベースにヒットする配列の抽出と、ヒットが見られた配列の相方を取得するときのフローチャートを下図に示しました。本マニュアルではこの5つのステップに沿って説明します(step3とstep4は一続きに処理されます)。
step 1 分割処理
巨大なsolexaファイルはまず複数のmulti FASTAファイルへと変換されます。
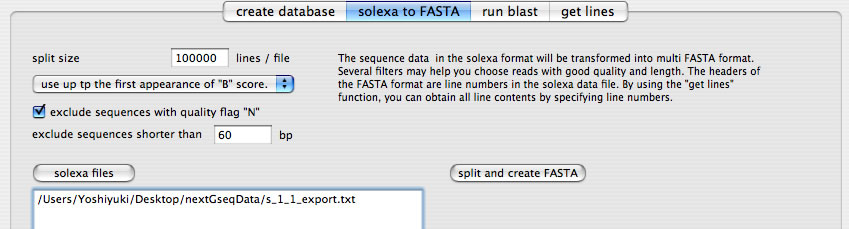
「solexa files」ボタンを押して、solexaデータファイルを選択します(複数選択可能)。
solexaファイルを何行ごとに処理するかを設定します。ここでは、10万行ごとに処理をする設定にしています。
solexaデータファイルでは各塩基の読み取りにスコアが付けられています。このスコア体系では「B」が最低スコアですが、Bが登場した以降の配列を切り捨てるには、プルダウンメニューから「use up to the first appearance of "B" score.」を選びます。スコアに関係なく、リードの最初から最後までを使うときは「use entire sequence」を選択します。
solexaデータファイルのリードそれぞれにはYまたはNの"quality flag"がついています。Nがついているリードを使わない設定にするには、「exclude sequences with quality flag "N"」チェックボックスをONにします。
ある長さ未満の配列を含めないようにするには、その長さを設定します。ここでは60 base未満のリードを使用しない設定にしています。
「split and create FASTA」ボタンを押します。
変換後の(複数の)multi FASTAファイルは、solexaファイルのあるディレクトリに新しく作られるフォルダ中に置かれます。multi FASTAファイル中、各配列のヘッダーにはsolexaファイル中の何行目にあったリードであったかが使われます。
solexaファイルを複数指定した場合、ファイルは順次処理されます。
step 2 blastデータベースの準備
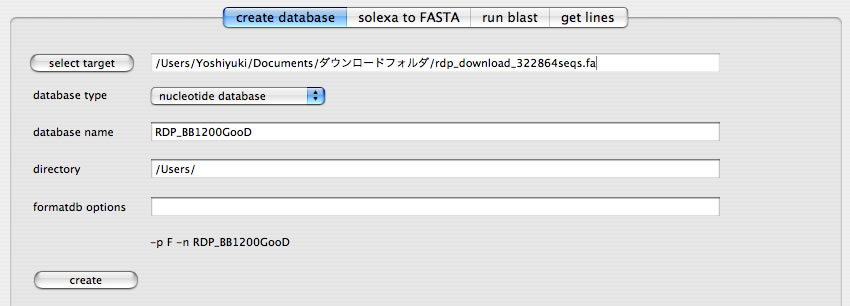
formatdbのGUIを利用してBLASTデータベースを作成します。「creat database」タブで必要な設定をして「creat」ボタンを押して下さい。
- 「select target」ボタンを押して選択するファイルはmulti FASTA形式である必要があります(GenBank形式は不可)。
- 「database name」には任意の名前を指定します(半角英数字のみ。スペース不可)。
- 「directory」には作成したデータベースの出力先を指定します。
「create」ボタンを押すと複数のファイルが作られます。一度作成したデータベースの名前は変更できません(Finderの機能でファイルの名前を変更すると、うまく行かなくなります)。
step 3 と step 4 blastの実行結果の解析
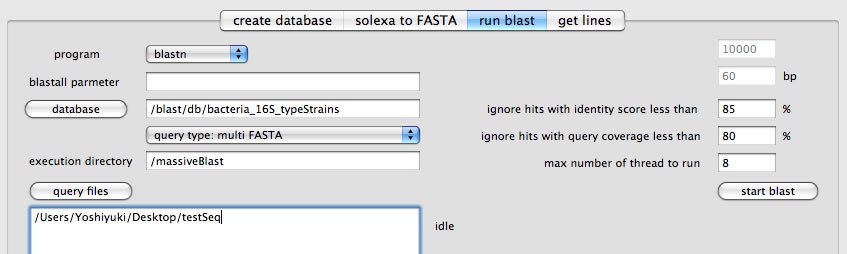
ここでは分散コンピューティングを利用しない前提で説明します。「run blast」タブを選択して、
- プルダウンメニューから実行するプログラムを選択します(blastnまたはblastx)
- (オプション)blastallのパラメーターを設定します(スペース区切り)。
- 検索対象のblastデータベースを「database」ボタンから選びます。どの拡張子のファイルを選んでもかまいません。
- query typeとしてmulti FASTAを選択します。
- 「execution directory」(実行ディレクトリ)を指定します(デフォルトでは「/massiveBLAST」となっています。必要に応じて変更して下さい。マルチユーザーで1台のMacを使っている場合、書き込み権限が無い可能性があります)。ここで指定したフォルダが作成され、その下層に必要なフォルダ、ファイルが作成されます。
- 「query files」ボタンから、multi FASTAファイルを格納したフォルダを選択します。フォルダを複数選択することもできます。
- どれぐらい相同性の低いヒットを無視するかを設定します(図では85%)。
- どれぐらいクエリカバレージが低いヒットを無視するかを設定します(図では80%)。
- 一度に実行するスレッドの最大数を指定します(図では8)
- start blastボタンを押します。
- blastallの"生の結果"は情報として多すぎますので、先の設定に従って相同性とクエリカバレージがある程度高いヒットのみが、ログファイルとともにユーザーのホームディレクトリに書き出されます。
step 5 ペアエンド配列の抽出
抽出データを表計算シートに貼付けて下さい。1列目がDNA配列、2列目がクエリ名です。先に説明した通りクエリ名はもともとsolexaファイルの何行目にそのリードがあったかを示しています。クエリ名(行番号)をコピーして、「get lines」タブの左側のテキストフィールドに貼付けます、
「query file」ボタンを押して、行データを抜き出す対象(ペアエンドの配列が格納されているsolexaファイル)を選択します。
「run」ボタンを押します。
指定した行に含まれるデータが右側のテキストフィールドに表示されます。
出力は、行番号が若い順になっています。気をつけて下さい。
分散コンピューテング、Xgridの使い方
ここでは分散コンピューティング「Xgrid」を利用した処理方法に付いて説明します。Xgridを利用するメリットがあるのは、ネットワーク上にCPUパワーを提供可能なMacが十分な数存在している時です。また、作業によっては分散処理にCPUコストがかかり過ぎ、却って遅くなる場合もあります。Xgridについて詳しくはAppleのページをご覧ください。
Xgridは、処理量の大きいタスクを、ネットワーク上でつながった複数のMacに分散して実行することで処理時間を短縮するためのシステムです。Xgridを利用すると、MassiveBLASTが動作しているMac(ここではクライアントと呼ぶ)から、BLAST処理の一部(ジョブと呼ぶ)が「コントローラー」の役割をするMacに投げられます。コントローラーはジョブを受け取るとコントローラーに登録されている「エージェント」Macのうち1台にジョブを任せます。エージェントでジョブが終了すると、ジョブの結果がコントローラー経由で、クライアントに返ってきます。複数のジョブを同時にコントローラーに投入できますので、エージェントがたくさんあればそれだけ早くジョブ全体が終了します。
Xgridを使用するには、1台の「コントローラー」と1台以上の「エージェント」に設定されたMacが必要です。一台のMacは同時に「コントローラー」にも「エージェント」にも「クライアント」にもなれます。手持ちのMacの一台を「コントローラー」および「エージェント」に設定する方法についてはApple社の解説をご覧ください。
Xgridを使ってMassiveBLASTを実行するには、BLASTのデータベースが、エージェントMacの所定のディレクトリにある必要があります(/ライブラリ/blast/db/)。またエージェントMacの所定のディレクトリにBLASTプログラムの本体(blastall)が所定の場所にある必要があります(/ライブラリ/blast/bin/blastall)。
MassiveBLASTで必要な設定:
- Use Xgridのチェックボックスをオンにします。
- コントローラーの名前(hostname)を入力します(コントローラーの設定の時につける名前です)。
- コントローラーに設定したパスワードを入力します。
- クライアントMacのCPU利用率が、何%を超えたときにXgridを利用するかを設定します(図で60%)。これは、全部のジョブをXgrid経由で処理するよりもクライアントMacで目一杯ジョブを処理した方が、全体として早く終了することが期待できるためです。マイナスの値を指定すると常にXgridにジョブを投入します。
- 「Max number of thread to run」の数を、エージェントのCPUの総数よりやや多めに設定します。

Apple社提供の、Xgrid Admin等を利用して、ジョブの進行具合をチェックしながら利用することを推奨します。MassiveBLASTでは分割して作成されたmulti FASTAファイル1つが、1つのジョブで処理されます。 実行中、クライアントで開始/終了したジョブの数、Xgrid上で開始/終了したジョブの数が表示されます。
注意とヒント
スレッドの数は利用可能なCPUの総数を少し上回るように指定して下さい。
blastallのパラメーターとして、-b 1を指定すると処理が早くなります(1クエリあたりtop 1件までしか出力しない設定です)。
Xgridは十分に理解した上でご利用ください。
solexaの生データの分割、multi FASTA化は、どの程度のサイズに分割した時にパフォーマンスが良いかご検討ください。
分割後のmulti FASTAフォルダには、自動生成したファイル以外のファイルを入れないでください。
ソレクサ由来でなくても、multi FASTA形式のファイルであれば、それをBLASTにかけることができます。