DataCounter
文字列よりなる集合がある時に、それぞれの文字列がいくつあるか数えてくれる機能です。
はじめに
2つの集合AとBがあるときに、Aにのみ含まれる要素、Bにのみ含まれる要素、AとB両方に含まれる要素を返す機能です。定性的あるいは定量的な解析が可能です。定性的な解析では、それぞれの要素の登場する回数は無視して解析されます。定量的な解析では、それぞれの要素について登場回数を考慮して解析されます。後者の機能を利用するとあるデータセットに含まれるそれぞれの要素についていくつあるかを知ることができます。1)ベン図の作成、2)更新されたデータの発見、3)処理前のデータと処理後のデータを比べることで、未処理データの抽出、等、使い方はいろいろです。
実行例
例として、あるゲノムAの中のCDSのN末端の3アミノ酸についてそれぞれがどのような頻度で見られるかについて調べてみます。GenBank形式のファイルからExtractFromGenBankFileを利用して、featureが「CDS」のエントリのqualifier 「translation」の値を一括取得します。得られた値を表計算シートに貼付け、エクセルの関数「LEFT」を利用して、先頭の3アミノ酸を抽出します(下図)。

先頭3文字を含む列を、DataCounterの左上のテキストフィールドに貼付けて、「run(count duplication)」ボタンを押します。先頭の「43」は空白のセルの数です。
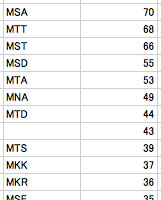
結果を表計算シートに貼付けて多い順に並び替えてみると、「MSA」を始めいくつかの3アミノ酸が多いことが分かります。
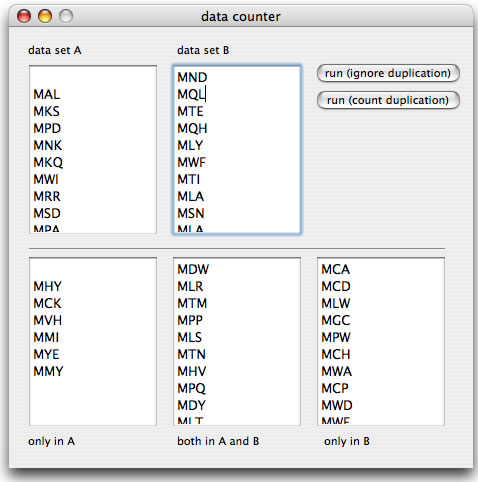
では別のゲノムBについて同様に調べてみることにして、ゲノムAにだけ見られる先頭3アミノ酸、ゲノムBにだけ見られる3アミノ酸はあるでしょうか?同様にゲノムBについて先頭3アミノ酸を抽出して、右上のテキストフィールドに貼付けます。そして今度は「run(ignore duplication)」ボタンを押します。下段左のテキストフィールドにゲノムAにのみある3アミノ酸が、下段右のテキストフィールドにゲノムBにのみ含まれる3アミノ酸が表示されます。
注意とヒント
文字の違いは厳密に区別されます。大文字と小文字は区別されますし、スペース文字などの非表示文字も考慮されます(「A」と「A 」は異なります)。
使い方は工夫次第でいろいろなことが可能です。